 Цель этой статьи — поделиться опытом и идеями реализации проекта, основанного на полном преобразовании текстов в семантическое представление и организации семантического (смыслового) поиска по полученной базе знаний. Речь пойдет об основных принципах функционирования этой системы, используемых технологиях, и проблемах, возникающих при ее реализации.
Цель этой статьи — поделиться опытом и идеями реализации проекта, основанного на полном преобразовании текстов в семантическое представление и организации семантического (смыслового) поиска по полученной базе знаний. Речь пойдет об основных принципах функционирования этой системы, используемых технологиях, и проблемах, возникающих при ее реализации.Зачем это нужно?
В идеале, семантическая система «понимает» содержание обрабатываемых статей в виде системы смысловых понятий и выделяет из них главные («о чем» текст). Это дает огромные возможности по более точной кластеризации, автоматическому реферированию и семантическому поиску, когда система ищет не по словам запроса, а по смыслу, который стоит за этими словами.
Семантический поиск – это не только ответ по смыслу на набранную в поисковой строке фразу, а в целом способ взаимодействия пользователя с системой. Семантическим запросом может быть не только простое понятие или фраза, но и документ — система при этом выдает семантически связанные документы. Профиль интересов пользователя – это тоже семантический запрос и может действовать в «фоновом режиме» параллельно с другими запросами.
Ответ на семантический запрос в общем случае состоит из следующих компонентов:
- Прямой ответ на вопрос и другая информация, касающаяся запрошенных и связанных с ними понятий.
- Семантические понятия, семантически связанные с понятиями запроса, которые могут представлять собой как ответ на вопрос, так и средство для «уточнения» запроса.
- Текстовые документы, мультимедийные объекты, ссылки на сайты по теме, которые раскрывают и описывают запрашиваемое смысловое понятие.
Новостной агрегатор – наиболее удобное информационное приложение для отработки такого семантического подхода. Можно построить работающую систему при относительно небольшом объеме обрабатываемого текста и высоком допустимом уровне ошибок обработки.
Онтология
При выборе онтологии основным критерием было удобство ее использования как для построения семантического парсера текста, так и для эффективной организации поиска. Для упрощения системы было сделано допущение, что можно не обрабатывать, или обрабатывать с большим допустимым уровнем ошибок часть содержащейся в тексте информации, которая предполагается не очень важной для поисковых задач (вспомогательная информация).
В нашей онтологии, простые семантические понятия (объекты) можно разделить на следующие классы:
- Материальные предметы, люди, организации, нематериальные объекты (например, фильмы), географические объекты и т.п.
- Действия, показатели ("продать", "инфляция", "сделать").
- Характеристики ("большой", "синий"), назовем их атрибутами.
- Периоды времени, числовая информация.
Основа информации, содержащейся в тексте, – это «узлы», образованные смысловыми сочетаниями понятий второго класса (действия) и первого класса. Объекты различных типов заполняют свободные валентности (роли) (например, цена – на какой товар? где? у какого продавца?). Можно сказать, что объекты первого класса уточняют, конкретизируют действия и показатели (цена – цена на нефть). В качестве «узлообразующего» объекта могут выступать не только объекты-действия, но и объекты первого класса («российские компании»). Этот подход аналогичен широко известным в западной компьютерной лингвистике фреймам (Framenet).
Узлы могут входить один в другой, когда один узел заполняет пустую роль в другом узле. В результате, текст преобразуется в систему вложенных друг в друга узлов.
Характеристики, примененные к семантическим понятиям первого и второго класса, как правило можно считать «второстепенной» информацией применительно к поисковым задачам. Например, в выражениях "сохраняются низкие цены на нефть","стабильные поставки нефти в Европу" выделенные курсивом атрибуты имеют меньшую значимость, тем другие объекты. Такая информация не входит в узлы, а привязывается к ним в привязке к определенному месту в документе. Аналогично к узлам привязываются числовая информация и периоды времени.
Рисунок ниже иллюстрирует семантическое преобразование двух несложных фраз. Цветные прямоугольники – это элементы шаблонов узлов, а прямоугольники над ними – элементы узла, построенного по этому шаблону.
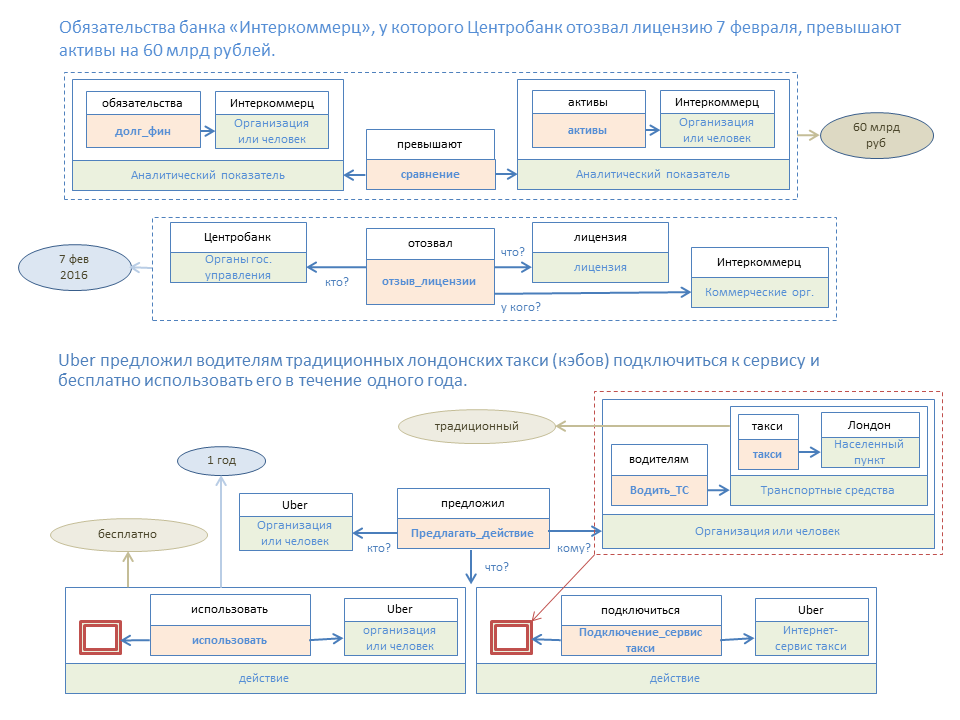
При таком подходе мы имеем два сорта информации:
- Определенный узел существует («цены на нефть»). Накопитель таких узлов назовем «Базой знаний».
- Этот узел существует в определенных местах документов с определенными атрибутами, числовыми значениями и периодами времени.
Такое разделение мы делаем для упрощения и ускорения поиска информации, когда, как правило, сначала ищем релевантные запросу узлы, а потом полученные данные фильтруем по вспомогательным параметрам.
Преобразование текста в семантическое представление
Основная задача семантического преобразования текста – структурировать содержащиеся там объекты в виде совокупности подходящих узлов. Для этого применяем систему шаблонов узлов, в которой для каждого элемента установлено условие на допустимый тип объекта. Типы формируют древовидный граф. Когда в шаблоне узла установлен для данной роли определенной тип объекта, то на эту роль могут подойти все объекты того же типа или «подчиненных» типов.
Например, в узле «торговые операции» активным объектом (продавцом или покупателем) может быть объект типа «человек или организация», а также объекты всех нижележащих типов (компании, магазины, культурные учреждения и т.д.). В шаблонах узлов заводим и синтаксические ограничения. В отличие от большинства других систем семантического анализа текстов, мы не делаем предварительный синтаксический разбор с формированием сети синтаксических зависимостей, а применяем синтаксические ограничения параллельно с семантическим анализом.
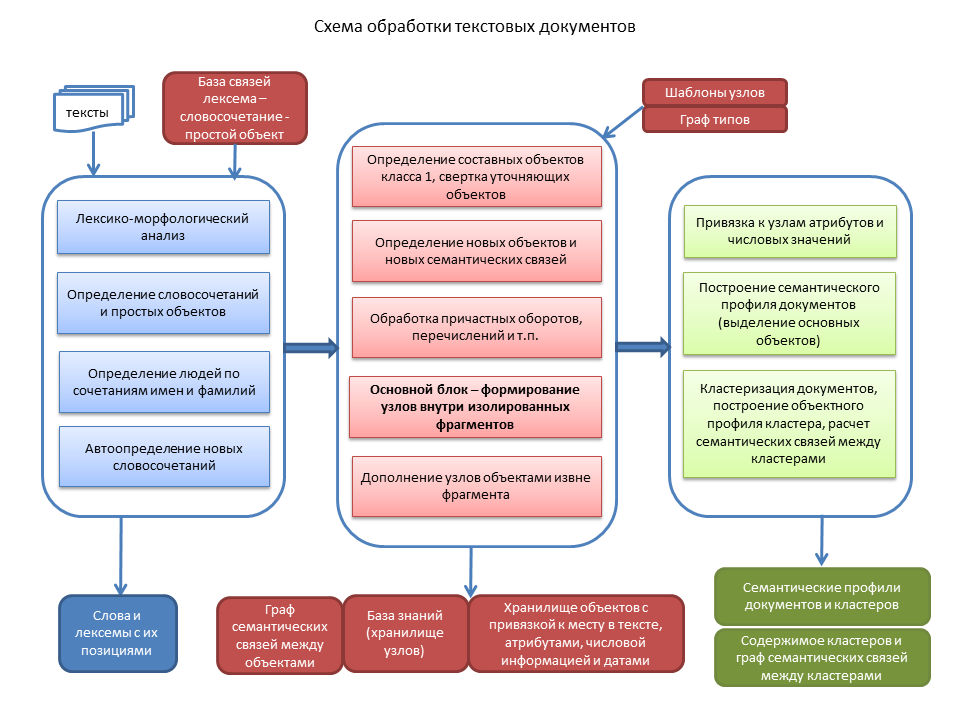
Кратко поясню основные этапы.
Сначала производится идентификация простых объектов, которые определяются отдельными словами или известными словосочетаниями. Далее, определяются комбинации имен и фамилий как указания на людей, и работает алгоритм анализа отдельных слов и последовательностей слов, которые могут быть неизвестными системе объектами.
На втором этапе формируем узлы на основе объектов класса 1 с уточняющими их объектами. Фразы типа «генеральный директор московской торговой компании «Рога и копыта» свертываются в один объект. Содержащаяся в этих узлах дополняющая информация («московская» как признак расположения и «торговая» как признак отрасли в этом примере) может быть добавлена в граф семантических связей для указанной компании. В следующей главе граф семантических связей рассмотрим подробнее.
Затем, текст нужно структурировать в виде последовательности независимых фрагментов, каждый из которых обычно содержит определенную фразу на основе глагола, и в идеале должен свернуться в один узел, который может включать в себя другие узлы. Обрабатываем причастные обороты и другие конструкции, а перечисления объектов класса 1, в том числе уже сформированные узлы, сворачиваем в специальные объекты.
После этого, для каждого фрагмента идет поиск подходящих узлов на основе объектов класса 2. Если для одного узлообразующего объекта сформировалось несколько узлов, остаются те, которые включают в себя максимальное количество объектов в данном фрагменте. Таким образом, на основе типа окружающих объектов происходит переход от семантически широких объектов вроде «идти» к узлу, имеющему ясный семантический смысл. Если при первичной обработке на месте омонимов возникли несколько параллельных объектов, то после этой обработки остаются только те объекты, которые вошли в узлы (т.е. семантически согласуются с соседними объектами).
Последний блок преобразования в семантическое представление – учет объектов, которые в тексте удалены от узлообразующих объектов, но по смыслу подразумеваются. Например, «В Москве тепло, идет дождь. Завтра похолодает, и пойдет снег». Семантический анализ конца предложения оставляет вакантной роль географического объекта, и по ряду признаков можно определить, что подходит «Москва».
Когда узлы полностью сформированы, к ним привязываем атрибуты, числовую информацию и периоды времени. Типична ситуация, когда период времени указывается только в одном месте текста, но относится к нескольким узлам по всему тексту. Приходится использовать специальный алгоритм для "распределения" периодов по всем узлам, где "не хватает" периода времени исходя из их семантического значения..
Наконец, в каждом документе определяем основные объекты ("о чем" этот документ). Помимо количества вхождений, учитывается участие объектов в узлах разных типов.
Имея богатую семантическую информацию, можно построить достаточно точную меру семантической близости документов. Объединение документов в кластер делаем при превышении мерой семантической близости определенного порога. Формируем семантические профили кластеров (основные объекты кластера, по ним обычно идет поиск) и сеть семантических связей между кластерами, позволяющую выводить «облако» документов, связанных по смыслу с определенным документом.
Как работает семантический поиск
Алгоритм семантического поиска состоит из следующих основных блоков:
Во-первых, если текстовый запрос, то нужно преобразовать его в семантическое представление. Отличия от описанного выше алгоритма обработки текстов документов диктуются, прежде всего, необходимостью очень быстрого выполнения поискового запроса. Поэтому, никакие узлы не формируем, а выделяем один или несколько блоков, состоящих из потенциально узлообразующего объекта и ряда объектов, которые, исходя из их типа и положения в запросе, могут относиться к этому узлообразующему.
При этом может быть сформировано несколько параллельных комбинаций, в одной из которых на следующем этапе нужно раскрывать через базу знаний комбинации типа «московские компании» в список конкретных объектов, а в другой не надо.
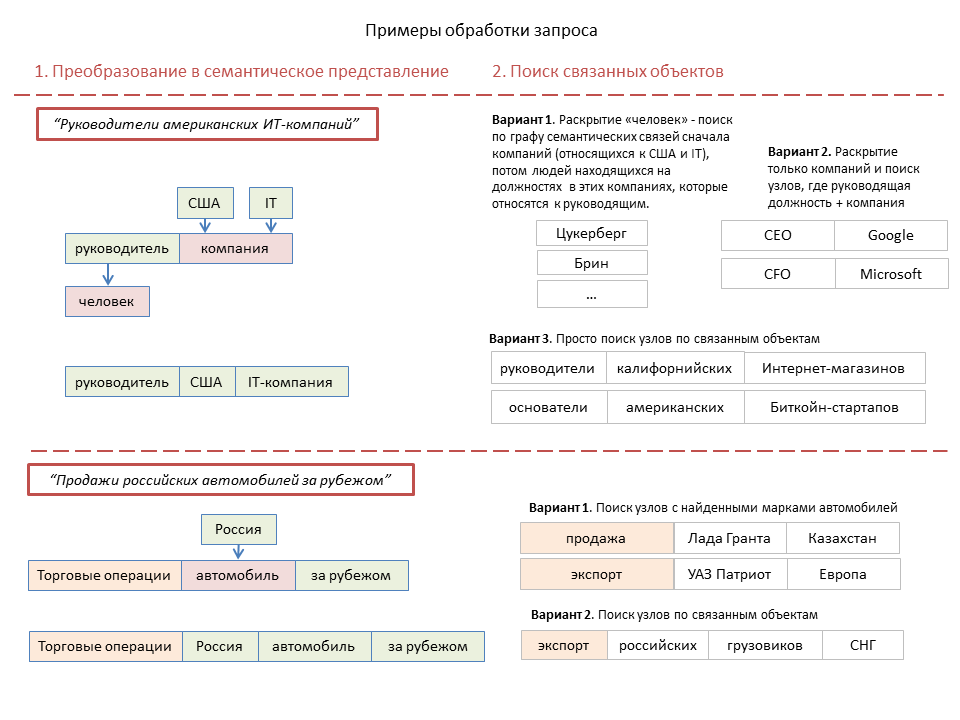
Следующий этап – поиск семантически связанных объектов и узлов. Для одиночных объектов класса 1 это выборка семантически связанных объектов. В случае комбинации «действие + объекты» идет поиск узлов, имеющих такой же или подчиненный тип узлообразующего объекта, и при этом имеющих в своем составе объекты, совпадающие или семантически связанные с объектами запроса. Также, производится раскрытие в список конкретных объектов комбинаций типа «московские компании» или «страны Европы».
Здесь используется древовидный граф семантических связей между объектами. Принцип его построения прост — к определенному объекту привязываются те "подчиненные" объекты, которые должны учитываться в поиске по данному объекту. Например, города подчинены государствам, политические деятели тоже подчинены государствам, компании подчинены странам или городам, руководители компаний подчинены компаниям. Для материальных предметов этот граф строится от более общих понятий к частным и частично совпадает с графом типов.
Для ряда объектов количество "подчиненных" может быть очень велико и возникает необходимость в выборе наиболее значимых. Для этого между элементами графа установлен числовой коэффициент семантической связи, который рассчитывается на основе значимости объектов. Для разных типов объектов значимость определяется по-разному, например, для компаний – исходя из экономических показателей (оборота) или количества сотрудников, для географических объектов – по количеству населения.
Далее, простые объекты и узлы, которые получены на выходе предыдущего этапа, ищем в объектных профилях кластеров. Если найдено мало кластеров, то идет поиск в объектных профилях документов.
Если поисковый запрос содержит объекты-атрибуты (характеристики), идет дополнительная фильтрация найденных документов по наличию привязанных к найденным узлам искомых атрибутов. Если в запросе есть лексемы, для которых в базе нет перехода к семантическим объектам, семантический поиск дополняется обычным текстовым поиском по лексемам.
Наконец, ранжируем найденные кластеры и документы, формируем сниппеты и прочие элементы выдачи (ссылки на связанные объекты и др.). Ранжирование обычно идет по степени семантической связи между объектами запроса и объектами, через которые найдены документы. Также, при ранжировании может быть учтен семантический профиль интересов пользователя.
Перед началом выполнения сложного запроса нужно делать анализ сложности обработки разных его компонентов, и строить порядок его выполнения таким образом, чтобы в процессе обработки возникало меньше промежуточных объектов или документов. Поэтому, порядок обработки не всегда может соответствовать описанному выше. Иногда может быть выгодно сначала найти документы на основе части запроса, а потом содержащиеся в них объекты фильтровать по отношению к оставшейся части запроса.
Отдельный алгоритм требуется для «широких» запросов – "экономика", "политика", "Россия" и т.п., которые характеризуются очень большим количеством связанных объектов и релевантных документов.
Например, с объектом «политика» связаны:
- Люди-политики – занимающие высшие государственные посты или авторитетные эксперты
- Организации — политические партии, органы гос. власти.
- Ряд событий и действий (выборы, назначения на определенные должности, деятельность Госдумы и др.).
В этом случае поиск ведем по относительно небольшому количеству актуальных кластеров с высокой степенью значимости, и ранжируем их по количеству свежих документов в кластере.
Основные проблемы реализации данного подхода и их решения
Проблема 1. Система должна "знать" все объекты, которые встречаются в текстах.
Возможные решения включают следующие:
- Применение семантической системы в области, где незнание или ошибки идентификации редких и малоизвестных объектов не критичны.
- Закачка объектов из существующих баз структурированной информации (DBpedia, Росстат и др.)
- Использование несложных алгоритмов автоматической идентификации типа объекта по уточняющим словам (например, "фильм «Марсианин»"), автоматического определения персон, а также словосочетаний, которые могут быть неизвестными системе объектами. При низкой вероятности ошибки объекты заводятся в базе автоматически, в случаях высокой вероятности ошибки используем систему ручной проверки.
- Для идентификации объектов рассматриваем возможность использовать машинное обучение, обучая систему по выборке уже известных объектов и опираясь на семантический тип объектов, окружающих неизвестный объект.
Проблема 2. Как сформировать шаблоны для всех возможных семантических узлов.
В решающих аналогичные проблемы распределения объектов по семантическим ролям англоязычных системах SRL (Semantic Role Labeling) используются алгоритмы машинного обучения с использованием уже размеченных корпусов. В качестве системы конструкций «действие + роли» используется, например, Framenet. Однако, для русского языка нет подходящего размеченного корпуса. Кроме того, реализация этого подхода имеет свои проблемы, обсуждение которых выходит за рамки этой короткой статьи.
В нашем подходе, как было описано выше, распределение объектов по ролям идет на основе соответствия типов объектов семантическим ограничениям, установленным для ролей в шаблоне узлов. Всего в системе сейчас около 1700 шаблонов узлов, большинство которых было сформировано полуавтоматически на основе фреймов Framenet. Однако, семантические ограничения для ролей приходится в основном устанавливать вручную, по крайней мере для наиболее часто встречающихся узлов.
Можно попробовать автоматическое формирование узлов с помощью машинного обучения на основе уже сформированных. Если есть некая комбинация объектов и слов (неизвестных системе) с определенными синтаксическими характеристиками, то можно формировать узлы, аналогичные уже существующим. Хотя по этим узлам все равно нужно будет вручную делать шаблоны, наличие такого узла все равно будет лучше, чем его отсутствие.
Проблема 3. Высокая вычислительная сложность выполнения многих семантических запросов.
Некоторые запросы могут включать в себя обработку очень большого количества промежуточных объектов и узлов и выполняться медленно. Эта проблема вполне решаема техническими методами.
- Необходима параллельность выполнения запросов.
- Анализ сложности различных путей выполнения запроса и выбор наиболее оптимального.
- Использование числовых коэффициентов в графе семантических связей позволяет ограничивать количество объектов, участвующих на промежуточных стадиях обработки запросов.
Рекомендуемая литература
- Цикл статей на Хабре по технологии ABBYY Compreno.
- Хорошая обзорная книга: "Semantic Role Labeling", Martha Palmer, Daniel Gildea, and Nianwen Xue, 2010.
- Dipanjan Das, Desai Chen, André F. T. Martins, Nathan Schneider, Noah A. Smith (2014) Frame-Semantic Parsing.








